



Vision AI Checkup
See how 20+ vision-language models perform on dozens of real-world tasks.
Run on 89 prompts.
Model
Score
Avg Time / Prompt
#1  Gemini 3 Pro Preview
Gemini 3 Pro Preview
80.7%
20.33s
#2  GPT-5.2
GPT-5.2
78.0%
6.94s
#3 OpenAI O4 Mini (High Reasoning)
75.9%
22.85s
#3 OpenAI O4 Mini (Medium Reasoning)
75.9%
14.26s
#3 GPT-5
75.9%
25.28s
#3 GPT-5 Mini
75.9%
12.67s
#3 GPT-5.1
75.9%
20.37s
#4 OpenAI O3 (Medium Reasoning)
74.7%
31.60s
#4 ChatGPT-4o (High Reasoning)
74.7%
14.60s
#4 OpenAI o3-pro
74.7%
51.63s
 Llama 4 Scout 17B
Llama 4 Scout 17B  Qwen 2.5 VL 7B
Qwen 2.5 VL 7B  Arcee.ai Spotlight
Arcee.ai Spotlight Explore Prompts
Explore the prompts we run as part of the Vision AI Checkup.
(p.s.: you can add your own too!)
Is the glass rim cracked? Answer only yes or no.

How wide is the sticker in inches? Return only a real number.

How many bottles are in the image? Answer only a number

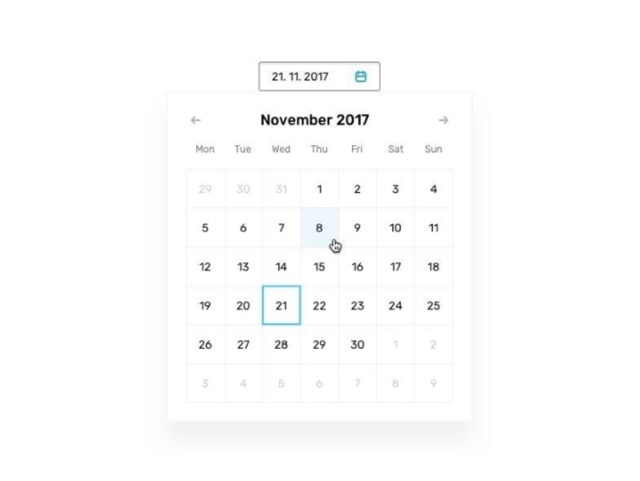
What date is picked on the calendar? Answer like January 1 2020
How much tax was paid? Only answer like $1.00

What is the serial number on the tire? Answer only the serial number.

About Vision AI Checkup
Vision AI Checkup measures how well new multimodal models perform at real world use cases.
Our assessment consists of dozens of images, questions, and answers that we benchmark against models. We run the checkup every time we add a new model to the leaderboard.
You can use the Vision AI checkup to gauge how well a model does generally, without having to understand a complex benchmark with thousands of data points.
The assessment and models are constantly evolving. This means that as more tasks get added or models receive updates, we can build a clearer picture of the current state-of-the-art models in real-time.
Contribute a Prompt

Have an idea for a prompt? Submit it to the project repository on GitHub!